RBFT(Redundant Byzantine Fault Tolerance) 합의 알고리즘 분석 (PBFT 합의 알고리즘과 함께)
RBFT(Redundant Byzantine Fault Tolerance) Consensus Algorithm with PBFT(Practical Byzantine Fault Tolerance).
본 글에서는 RBFT 합의 알고리즘의 동작방식에 대해서 논문을 바탕으로 살펴본다. 논문은 한 문장 한 문장 밀도가 높은 글이어서 해당 분야의 도메인 지식(domain-knowledge)이 없으면 읽기 힘들다. 그래서 논문을 이해하기 위해 부족한 내용이나 참고할만한 내용들을 조금 첨언했다. 최종 목적은 이 논문에서 다루는 RBFT 가 실제 블록체인 상에서 합의 알고리즘으로 동작하기 위해서는 어떤 이슈가 있을지 분석하는 것이다. RBFT 가 PBFT 의 단점을 보완하기 위해 나온 합의 알고리즘이기 때문에 자연스럽게 PBFT 의 이슈도 살펴볼 수 있을 것이다.
RBFT 에 대해서 이미 알고 있는 분은 분석 파트만 보면 될 것 같다.
PreRequsite
다음과 같은 내용을 알아야 본 글을 이해하는데 어려움이 없다.
- BFT 에 대해서
- 합의 알고리즘에 대해서 이더리움 white-paper 정도의 지식
- 이전글 블록체인 합의 알고리즘 기초
여기서 말하는 기존 BFT 들에서 사용하는 용어와 동작하는 공통적인 방식을 간단하게 짚고 넘어가자.
replica- 합의에 참여하는 노드들.primary- 클라이언트로 부터 온 요청을 ordering 하는 작업의 결정권을 가진 replica.
합의 대상은 클라이언트로부터 온 요청들의 순서를 결정하는 ordering 이다. (transaction validation 까지 같이 수행해서 합의하는 경우도 있다. e.g. Hyperledger-Indy) 보통은 클라이언트로 부터 온 요청은 합의에 참여하는 모든 노드 (혹은 다수의 노드)가 broadcast 로 받은 상태에서 시작하기 때문에 ordering 결과를 합의한다. ordering 의 결정권을 가진 primary replica 가 ordering 을 마치면 그것을 담은 메세지를 non-primary replica 들에게 보낸다. non-primary replica 들은 primary 가 보낸 ordering 의 validation 을 체크해서 해당 ordering 에 합의를 한다. 합의를 마치면 해당 ordering 에 포함된 요청들이 실행된다.
Introduction
기존의 BFT는 일반적인 합의 과정에서 빠른 성능을 내는데 관심이 있었다. 하지만 이제는 장애 상황을 어떻게 자동으로 인식하고 이에 잘 대처해서 성능이 안정적으로 나오도록 하는, 즉 robust 로 관심이 옮겨지고 있다. 이 논문에서 언급하는 기존 BFT 들(Prim, Aardvark, Spinning)는 장애 상황에서도 좋은 성능을 보여줬다. 하지만 robustness 를 측정했을 때는 효과적이지 않았다. 최소 78% 의 성능 저하를 보여서 상용소프트웨어에서 사용할 수 없는 수준이다.
robustness 가 떨어지는 이유를 간단하게 짚어보면 다음과 같다.
- primary 라고 불리는 replica 에 dedicated 되어있기 때문에.
- primary 가 악의를 가지는 것을 감시하고 복구할 수 있는 방법이 있지만, primary 가 지능적으로 공격할 수 있음.
- primary 가 지능적으로 공격할 때 다른 replica 들의 성능을 급격히 떨어뜨림.
그래서 RBFT 에서는 primary 에 의존적인 방식을 피하는 방향을 제시한다.
기존에 reader-free BFT 방식을 제시하는 논문(F. Borran and A. Schiper. Brief announcement: a leader-free byzantine consensus algorithm. In DISC, 2009.)이 있다. 이 방식에서는 primary 에 의존하지 않기 위해서 자신이 받은 메세지가 correct replica 로부터 받았다는 것을 확신하기 위해서 timeout 을 기다리는 방식을 택하고 있다. 하지만 이런 timeout 을 기다리는 방식 역시 throughput 이 떨어지는 성능저하를 가져오기 때문에 실용적이지는 않다.
System Model
논문에서 가정하는 시스템 모델은 논문( L. Lamport. Lower bounds for asynchronous consensus, 2004)에서 다루는 것과 같다.
- 하나의 프로세스가 위험하다면 그 노드(머신)가 위험하다고 판단한다.
- Faulty 노드나 클라이언트는 같은 합의 인스턴스내의 replica 들을 위험하게 만들 수 있다.
- Async N/W 는 synchrony interval 을 가진다.
- PBFT 와 같은 맥락을 가진다.
시스템 모델에 대한 자세한 내용은 위 논문이나 PBFT 논문에서 자세히 설명하고 있다. 결론적으로 알아야 할 것은 대처 가능한 장애 노드수는 f = (n-1)/3 이라는 점이다. 즉 동시에 1/3 이상의 노드가 악의적인 공격을 가하면 합의를 신뢰할 수 없다.
기존 알고리즘 동작 방식 및 단점
여기서는 Prim, Aardvark, Spinning 만을 다루는 이유는 이 합의 알고리즘들은 모두 robustness 문제를 해결하기 위해서 디자인 된 것이기 때문이다. 이 전에 유명했던 PBFT, QU, HQ, Zyzzyva 모두 이미 robust 이슈를 가지고 있다는 것들이 판명난 것들이기 때문에 자세히 다루지는 않는다.
참고로 PBFT 는 이 논문에서 다루는 Aardvark, Spinning, RBFT 의 기반 알고리즘이고 많은 블록체인들(Cosmos, Neo, Hyperledger-R3)에서 사용하고 있기 때문에 알아야할 필요가 있다. PBFT 에 대한 자세한 내용 역시도 인터넷에 쉽게 설명한 자료들이 많으니 검색해서 이해하고 오면 좋겠다. PBFT 에서 다루는 핵심을 간단하게 말하면 3PC(3-Phase-Commit) 방식으로 합의를 도출한다는 것이다. 클라우드 또는 클러스터 운영 환경에서 클래스를 배포하거나 설정 변경 등을 동시에 여러 노드에 할 때 많이 사용하던 2PC(2-Phase-Commit) 방식에서 PREPARE 상태인지를 확인하는 PRE-PREPARE 과정이 앞에 한 단계 추가되었다고 보면된다.
A. Prim
동작 방식
- 클라이언트는 요청을 어떤 하나의 replica 에게 보낸다.
- replica 들은 주기적으로 이 요청들을 교환한다.
- replica 들은 현재 자신이 받은 요청들의 ordering 을 가지고 있고 primary 로부터 ordering 메세지가 오기를 기다린다.
- primary 는 주기적으로 replica 들에게 ordering 메세지를 보낸다.(요청이 없다면 빈 메세지라도 보낸다.)
- 이렇게 replica 들이 primary 로 부터 오는 메세지의 기대빈도를 가질 수 있다. 또한 이 기대빈도의 정확성을 개선하기 위해서 N/W 성능을 각 replica 들이 모니터링한다.
- 모니터링 방식은 주기적으로 자신이 맺은 페어 replica 들과 round-trip 시간을 측정해서 maximum delay 를 계산한다. 이 메세지는 정상 primary 에게서 온 메세지를 자신의 것과 비교해서 두 개의 ordering 으로 나누기 위해 사용한다.
- primary 가 replica 들이 기대한 것보다 메세지 전송이 느려지거나, ordering 이 다수의 replica 들과 틀리면 primary 를 교체한다.
이 방식이 robust 하지 않은 이유는 네트워크 모니터링이 부정확하다면 기대 빈도 값이 늘어날 수 있다. 즉, primary 가 보내는 ordering message 가 너무 늦게와서 합의가 늦어질 수 있다는 것이다. 합의가 늦어지면 네트워크의 요청 처리량(throughput)은 떨어질 수 밖에 없다.
어떻게 Prim 합의방식을 공격할 수 있는지 예를 들어보면,
- round-trip 시간을 증가시키기 위해서 primary 가 악의적인 클라이언트를 이용한다.
- 이 악의적인 클라이언트는 다른 요청들보다 무거운(메세지 크기가 큰) 요청을 보낸다.
- 이거는 replica 들이 측정하는 round-trip 타임을 증가시키고 이는 primary 로 부터 ordering message 를 기다리는 기대 시간을 증가시킨다.(기대빈도가 낮아진다.)
- 이렇게 기대 시간이 길어지면 primary 는 정직한 클라이언트로부터 온 메세지를 딜레이 시킬 수 있는 기회를 갖는다.
- 이렇게 하면 악의적인 primary 검출이 불가능하고, 이 작업을 반복할 수록 네트워크 전체의 요청 처리량은 떨어진다.
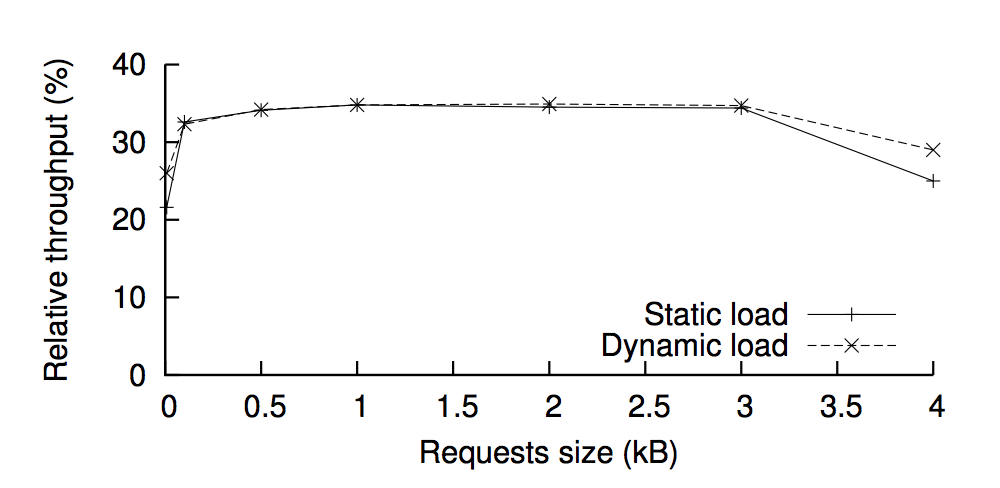
그래서 요청의 크기에 따라서 처리 성능이 어떻게 떨어지나 비교했더니, 악의적인 공격이 없는 경우(fault-free case)와 비교했더니 최소 22% 의 처리 성능을 보였다. 즉, 최대 78%의 성능 저하가 발생했다.
B. Aardvark
Aardvark 는 PBFT 를 기초로 하고 있다. PBFT 와 다른 특징이라고 한다면 primary replica 를 규칙적으로 바꿔준다는 것이다. primary 를 바꾸는 방식은 크게 3가지가 있다.
1.규칙적인 view 변화
primary 가 변할때, view 라고 명명하는 새로운 설정이 시작된다. 이 view 를 주기적으로 바꿔주는 것이다. 이렇게 주기적으로 primary 를 바꿔주면, 악의적인 primary 가 있더라도 해당 주기 이후에 교체될 것이기 때문에 악의적인 primary 발생시킬 수 있는 처리량 감소를 일정 수준 제한할 수 있다. 또한 primary 가 되려면 최근 N 개의 view primary 들의 처리량 성능의 90%를 달성해야 한다. primary 가 5초 동안 이렇게 요구되는 처리량 성능을 달성하면, non-primary 들이 요구하는 처리량 성능을 0.01% 씩 올린다. primary 가 실패하면 그 때 primary 를 바꾼다. 이는 primary 가 되는 노드를 처리량 성능 통계가 높은 것들로 선별할 수가 있고, 악의적인 의도를 가지더라도 빠르게 primary 에서 내려주므로 네트워크의 처리량 감소 폭이 낮도록 제한할 수 있다.
2.Heartbeat Timer
추가적으로 최소 처리량 기대치를 primary 가 ordering 메세지를 보내는 빈도를 모니터링 해서 계산한다. ordering 메세지를 받으면 heartbeat timer 를 시작시키고, primary 가 다음 메세지를 보내기 전에 타이머가 만료되면 primary 를 바꿀 것인지 vote 를 할 수 있다.
3.Other ways
또 다른 여러가지 방법을 적용할 수 있는데, 예를 들어서 NIC 를 분리하는 방법을 소개한다. NIC 를 분리하면 클라이언트의 요청에 의해서 replica 들 사이의 통신이 느려지지 않을 수 있다.
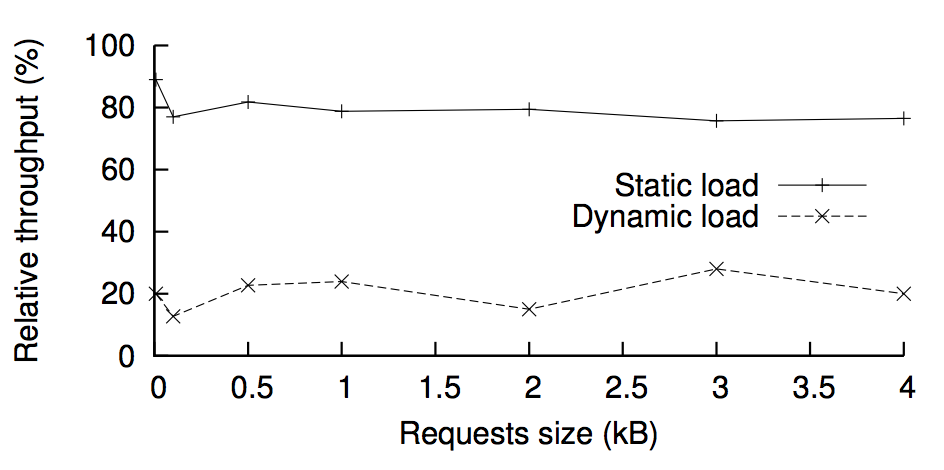
이 방법은 네트워크를 구성하는 노드들이 다양하고 많아질수록 따라서 악의적인 primary 에 의해 받을 수 있는 데미지도 더 많이 제한이 된다. 그래서 클라이언트가 보낼 수 있는 최대치 요청량에 근접한 처리량을 보여준다. 실험 결과 static load (일정한 부하) 일때, 최소 처리 성능이 76% 정도임을 보여준다.
하지만 단점은 dynamic load(동적인 부하) 를 주었을 때 처리량이 급격히 감소한다는 것이다. 처리량 성능이 늦게 나오도록 heavy 한 요청을 주면 replica 들이 primary 에게 기대하는 기대치가 낮아진다. 이렇게 낮아진 때에 정상적인 요청들을 받으면 악의적인 primary 가 상대적으로 오랜시간 primary 지위를 누리면서 ordering 을 늦게 처리할 수 있다. 실험 결과 dynamic load 일 때, 13% 까지 처리 성능을 끌어 내릴 수 있었다. 즉, 성능이 87% 감소할 수 있다는 것이다.
C. Spinning
Spinning 도 PBFT 기반 프로토콜이고 Aardvark 처럼 주기적인 primary 교체를 한다. Spinning 의 특징은 primary 가 한번의 배치 요청을 ordering 한 뒤에 자동으로 교체된다는 점이다.
동작 방식
- 클라이언트는 모든 노드에 요청을 보낸다.
- non-primary replica 들은 Timer 를 시작하고 primary 로 부터 ordering 메세지를 기다린다.
- 타이머가 만료되면 현재 primary 는 blacklist 에 추가되고 다른 replica 가 primary 가 된다. 이 블랙리스트에 들어간 replica 는 다시는 primary 가 될 수 없다.
- 성공적으로 ordering 메세지를 받으면, primary 는 자동으로 교체되고 타임아웃은 초기값으로 리셋된다. primary 에서 내려간 replica 는 나중에 또 primary 가 될 수 있다.
- 여기서 사용되는 타임아웃 값은 system parameter 로 세팅된 값이다.
Spinning 이 Aardvark 와 비교해서 개선한 점은 모니터링에 의존하지 않고 바로 primary 를 바꿔주고 악의적인 primary 는 다시 primary 가 될 수 없다는 점이다. 이는 Aardvark 가 목표로 했던 악의적인 primary 가 끼칠 수 있는 성능저하를 최소화 시키겠다는 목표에 한 발짝 더 다가간 모습이다.
하지만 Spinning 에도 취약점이 있다. 바로 악의적인 primary 가 타임아웃 시간내에서 지연을 시킬 수 있다는 점이다. 어자피 타임아웃 내에서는 괜찮다고 판단해서 설정한건데 그게 뭐 어때? 라고 질문할 수도 있다. 하지만 테스트 결과를 보면 괜찮다고 할 수 없다.
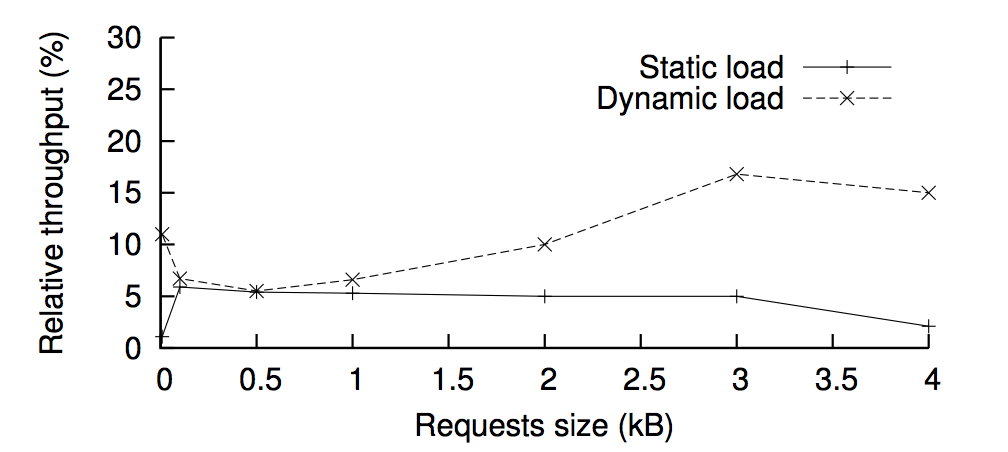
보는 바와 같이 1-4.5% 까지 처리 성능이 낮아진다. 즉 성능저하를 99%까지 시킬 수 있다는 점이다. 방법은 단순하다 하나의 primary 후보가 될 replica 만 사용하면 된다. timeout 시간 내에 primary 가 처리를 지연시킨다. 이 경우 타임아웃이 발생하지 않았으므로 해당 primary 는 블랙리스트에 등록되지 않고 primary 의 지위를 잃게 된다. 즉, 이후 미래의 ordering 메세지도 지연시킬 수 있다는 것이다. 또 다시 차례는 오니까.
- 단, 네트워크에 참여하는 노드가 많아질 수록 악의적인 replica 가 영향을 미치는 정도가 낮아진다. 하지만 PBFT 계열 자체가 네트워크에 노드가 많아질수록 합의에 시간이 오래걸린다는 점을 보면 노드를 늘리는 것은 해결책이 아니다.
정리
요약하면 위 프로토콜 들은 primary 가 조금만 똑똑하게 악의적인 공격을 한다면 엄청난 성능 저하를 일으킬 수 있다.
- Prim : 네트워크가 어느 정도의 sync 를 맞춰줄 때 robust 하다. N/W 의 다양성이 늘어남녀 primary 가 심각한 데미지를 줄 수 있다.
- Aardvark : dynmaic load 에서 성능을 보장하지 못한다.
- Spinning : 현재 primary 가 정상인 경우에만, 3f+1 노드에서 2f+1의 리퀘스트에 대해서만 robust 하다. 악의를 가진 replica 가 primary 가 되었을 때 너무 취약하다.
위 알고리즘들이 변화해온 양상을 보면 마치 리눅스의 스케줄러의 변화 과정과 비슷하다는 생각을 한다. 처음에는 단순한 아이디어로 스케줄링을 하다가, 기능 개선을 위해서 모니터링을 하고 통계기반의 스케줄링을 했다. 커널 2.6버전 부터 현대 리눅스의 기반이 대거 갖춰졌는데, 이때 비로소 completely fair algorithm 으로 스케줄링을 하기 시작했다. 단순 아이디어 -> 통계 기반 스마트화 -> 결국 fair 이런 식으로 발전해왔다. 이는 비단 OS 스케줄링이나, BFT 문제 뿐만 아니라 다른 소프트웨어에서도 종종 찾아볼 수 있다.
RBFT
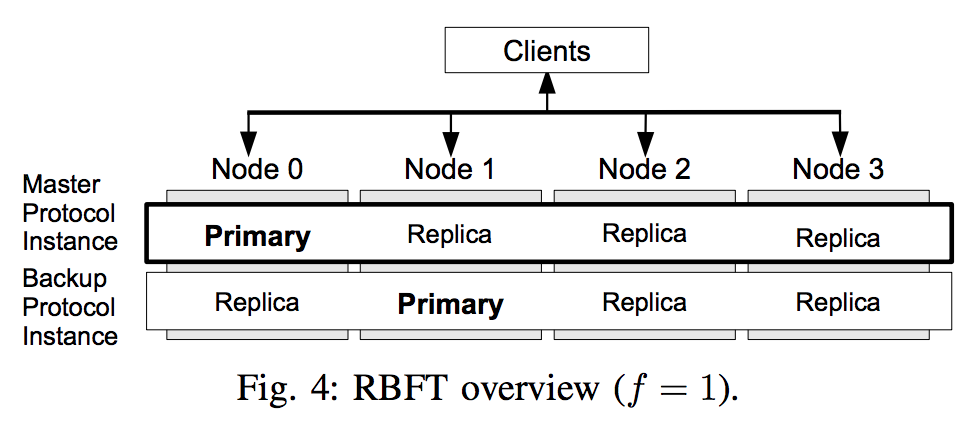 노드 구성
노드 구성
- 각 노드는 f+1 개의 프로토콜 인스턴스를 구동한다.(그림에서 가로행)
- 각 인스턴스별로 3f+1 노드 중 하나의 primary 노드를 갖는다.
- 각 인스턴스 별 primary 를 중심으로 ordering 및 합의를 진행한다.
- 프로토콜 인스턴스 중 ordering 메세지의 제안 권한을 가진 인스턴스를 master, 나머지 인스턴스를 backup 인스턴스라고 한다.
- 따라서 최종 합의 결과는 f+1 개의 결과를 갖는다.
- 클라이언트는 각 인스턴스의 primary 로부터 f+1 개의 타당한 합의 결과를 받을 수 있다.
- master 인스턴스가 악의가 있는 primary 노드로 구성되어있다고 판단되면, master 인스턴스 권한을 내리고 backup 인스턴스들 중에 모니터링 기준 또는 투표로 master 인스턴스를 선출한다.
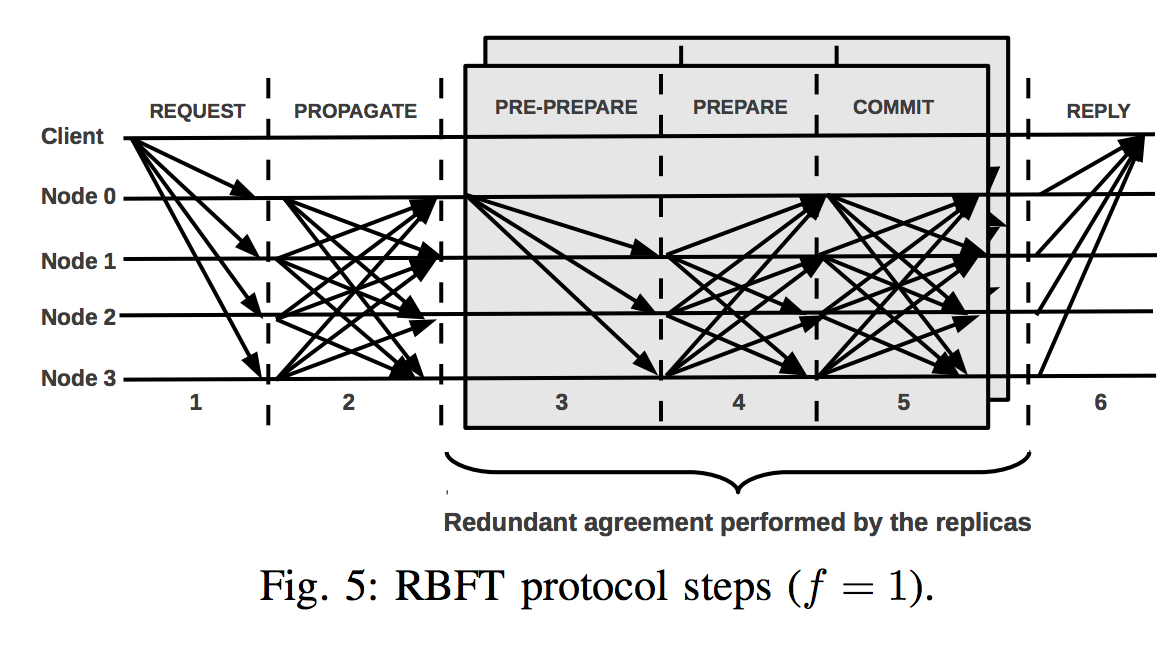
동작 방식
- 클라이언트는 모든 노드에게 리퀘스트를 보낸다.
- correct node 는 리퀘스트를 모든 노드에 전파시킨다.
- 메세지 암호화 검증과정
- 클라이언트로부터 메세지를 받으면 PROPAGATE 메세지를 다른 노드에게 전달. PROPAGE 메세지를 받았어도 다른 노드에게 PROPAGATE 한다.
- 하나의 노드가 f+1 개의 전파메세지를 받으면 f+1 프로토콜 인스턴스에 대해서 locally ordering 을 수행할 준비가 되었다고 판단한다.
- 오더링 수행할때 리퀘스트 전체에 대해서 할 필요는 없고, 클라이언트 id, 요청 id, digest 가지고만 하는 등으로 최소화 하는게 좋다.
- 3PC 로 ordering 을 실제 수행함. (헷갈리지 말아야 할게 3PC 부터는 노드단위가 각 인스턴스의 primary 중심으로 진행됨.)
- 여기서는 primary 가 PRE-PREPARE 메세지를 보낸다.
- 그리고 모든 replica 에게 PEPARE 메세지를 보내서 PRE-PREPARE 에 응답한다. (아까 PROPAGATE 과정에서 f+1 리퀘스트 받은 replica 만 해당)
- 하나의 instance 에 대해서 각 replica 가 2f 의 메세지를 받으면 COMMIT 메세지를 broadcast 한다.
- replica 가 2f+1 개의 일치하는 COMMIT 메세지를 받으면 ordered 요청 를 자기가 돌고 있는 node 에게 보낸다.
- 요청 실행, 클라이언트 에 응답한다.
- 노드가 master replica 에게 ordered 요청을 받을 때마다 리퀘스트를 실행한다.
- 실행결과를 클라이언트 에게 보냄
- 클라이언트 는 f+1 개의 valid 결과를 받게 된다.
이 외에도 클라이언트들을 대상으로 latency 를 계산해서 fairness 를 보장하도록 하는 방식, 어떻게 모니터링해서 master 를 내리는지 등의 내용이 더 있다. 본 글의 목적은 논문을 소개하는 것이 아니라 해당 알고리즘에서 발생가능한 이슈를 분석하는 것이므로 합의 알고리즘의 핵심 논리만 간략하게 설명했다.
RBFT 프로토콜은 이러한 방식으로 기존에 악의적인 primary에 의해서 발생할 수 있는 성능 저하를 최소화 시켰다. 논문에 근거한 테스트 케이스로는 부하를 늘려도 성능 저하가 최대 3%까지 일어나지 않았다고 주장한다. 그렇다면 단점은 없는 것일까?
블록체인 네트워크 적용에 고려해야 할 이슈
이 파트부터는 논문에는 나오지 않은 내용으로, 작성자의 의견임을 밝힙니다.
f를 어떻게 추정할 것인가? (PBFT & RBFT)
논문 L. Lamport. Lower bounds for asynchronous consensus, 2004 에서 가정하는 시스템모델, 즉 이 논문에서 다루는 모든 BFT 들은 장애 허용을 네트워크를 구성하는 노드 수가 3f+1 인 경우를 가정하고 있다. 이 말은 네트워크를 운영할 때 악의적인 노드가 최대 f 개 이하일 것을 추정해서 f 값을 산정하고 3f+1 개 이상의 노드를 합의에 참여하도록 네트워크를 운영해야 한다는 말이다. 그럼 이 f 를 어떻게 추정할 것이냐가 중요한 이슈이다. 이것은 public 이든 private 이든 똑같이 적용된다. f 를 너무 적게 잡으면 적은 수의 노드를 조작해서 네트워크 전체를 조작하는게 가능해진다. 반대로 f 를 너무 크게 잡으면 합의에 참여해야 하는 노드들이 너무 많아진다. f 의 추정 기준을 어떤식으로 하던지 네트워크에 참여하는 노드 수가 많아지면 f의 추정치는 그에 비례해서 늘려야만 하는 것은 피할 수 없다.
RBFT 의 단점
1.운영 노드 오버헤드
추정된 f의 수가 적다면 상관 없지만 f 가 클 경우, 하나의 노드에서 f+1 개의 합의 프로토콜 인스턴스를 구동시켜야 하는 것이 큰 오버헤드가 될 수 있다. 즉 합의에 참여하는 모든 replica 인스턴스의 수 n = [노드수(3f+1) x 노드당 프로토콜 인스턴스 수(f+1)] 개가 된다. 위에서 언급한 것 처럼 네트워크가 커질수록 f 의 추정치는 비례해서 늘어날 수 밖에 없다. 그렇다면 합의 과정에 참여하는 replica 들에 의한 합의 결정에서의 복잡도는 f의 제곱에 해당하는 복잡도를 가진다. 물론 모든 replica 인스턴스에서 요청의 ordering 과 실행(execute)을 하지 않고 노드당 한 번씩만 수행해서 소모하는 프로세싱 파워는 사실상 다른 프로토콜들과 큰 차이는 안날 것이다. 하지만 primary 와 non-primary-replica 들 간의 통신 오버헤드는 f의 제곱이 된다. 합의 과정에 걸리는 복잡도가 기존의 3f+1 개의 합의만 필요했던 알고리즘들에 비해 복잡해지는 것은 부정할 수 없다. 그리고 더욱 중요한 것은 이 복잡도에 의해서 합의 알고리즘이 어떤 문제를 일으킬 수 있는 지에 대해서는 전혀 이야기 하지 않는다는 것이다.
이 논문에서 테스트 결과를 무작정 신뢰하면 안되는 이유는 바로 f=1, 2 인 경우만 수행했다는 점이다. 성능 테스트 결과 그래프만 보면 그럴싸 하지만, f가 늘어날 경우는 고려하지 않은 아키텍처라는 것이다. 특히, 테스트에서 사용하는 노드 머신을 프로토콜 인스턴스 수(f+1)만큼 NIC 를 분리해서 부착했는데, 실제로 이런 머신환경을 상용 소프트웨어에서 가정한 다는 것은 어불성설이다. 하드웨어 가상화 기술을 사용해서 소프트웨어적으로 NIC 를 분리한다고 해도, 하나의 NIC 당 성능을 일정 수준 이상 보장해 주려면 프로토콜 인스턴스의 수가 늘어날 때마다 HW 에 성능이 더 높은 NIC를 부착해주어야 하는 것은 피할 수 없다. 이는 private 네트워크에서 구성한다고 해도 무리가 가는 하드웨어 아키텍처이다. 그래서 f가 2일때 까지만 테스트할 수 밖에 없었는지도 모른다. 자충수이다. 또한 소프트웨어 아키텍처가 하드웨어 아키텍처에 dependency 가 있다니, 이것은 현대 소프트웨어 상상할 수 없는 모델이다. 아직도 한국의 많은 은행 기반 시스템이 IBM 메인프레임의 굴레에서 벗어나지 못하고 있는 것을 떠올려보자. 끔찍하다.
2.하드웨어 아키텍처 dependency
NIC 를 늘리지 않고 평가를 한다면 각 프로토콜 인스턴스의 primary 의 성능을 모니터링 하는 로직의 신뢰를 깨뜨린다. 왜냐하면 하나의 NIC 를 가지고 여러 인스턴스가 공유해서 쓴다면, 어떤 인스턴스의 성능 측정치가 다른 인스턴스에 의해 영향을 받기 때문이다. 앞선 인스턴스가 NIC 에서 copy 해가는데 시간을 많이 써서, 두 번째 NIC 값을 읽어가는 경우가 발생했다면 나중에 NIC를 이용하는 인스턴스 일수록 안좋은 평가를 받을 수 밖에 없다. 따라서 의도치 않게 master 합의 인스턴스가 다른 인스턴스로 교체될 수 있다.
3.클라이언트 부하
RBFT 에서 클라이언트는 하나의 요청에 대해서 합의 프로토콜 인스턴스 수 만큼 응답을 받게 된다. 그 중에 f+1 개의 valid 응답을 확인하고 valid 결과인지 확신할 수 있다. 이 방식은 클라이언트에게 불필요한 오버헤드를 증가시킨다. 클라이언트가 원하는 것은 정확한 하나의 결과인데 최소 f개의 응답을 더 받고 비교까지 해야 한다는 것이다.
이를 해결하기 위해서 실제 운영환경에서는 PROPAGATE 과정과, 최종 클라이언트에게 하나의 응답만 주기위해 f+1 개의 응답 validation 을 체크하는 게이트웨이 역할을 하는 노드가 필요하다. 하지만 이렇게 하면 게이트웨이로 인해서 중앙화가 발생하게 된다. 그렇게 되면 네트워크에서 그 게이트웨이도 역시 안전한지 판단이 필요하다. 악의적인지 아닌지 판단해야하는 로직이 개발된다고 해도 이는 최종 클라이언트에게 응답을 더욱 지연시키게 될 것이다.
합의 알고리즘의 안정성을 위해서 클라이언트에게 판단하는 작업을 일부 전가시켜 버렸다. 또한 클라이언트의 역할과 책임, 안정성 이슈는 논외로 하고 실험 결과를 보였다는 것은 아쉬운 점이다. 과연 RBFT 클라이언트는 이 합의에 즐겁게 참여할 수 있을까?
연구해볼만한 포인트
1.모니터링 모델을 없앤다.
애초에 모니터링 평가 모델을 없애보면 어떨까? 리눅스 스케줄링 알고리즘이 발전해 온 것 처럼. Aardvark 에서 Spinning 으로 통계 기반에서 통계 없애는 것으로 변화해 온 것처럼 말이다. RBFT 도 모니터링 값에 의존해서 master 를 바꾸지 않고 random 하거나 static 한 지표로 master 노드를 바꾸는 방식을 연구해보면, NIC 추가 없이 일반 노드들도 합의에 참여할 수 있는 방법을 찾을 수 있을 것 같다. 하지만 그렇다고 하더라도 f 가 늘어남에 따라 운영 오버헤드(특히 네트워크 자원을 많이 쓰게 되는 것)를 피할 수는 없을 것 같다.
또한 public 할때 어떻게 해결할 수 있을지는 여전히 큰 이슈이다. 그래서 private 블록체인인 Hyperledger-Iroha 정도만 RBFT 를 쓰고 Cosmos, Neo 등의 public 블록체인들은 이 논문에서 다룬 바와 같이 단점이 이미 밝혀졌음에도 PBFT를 택하고 있다. 논문을 처음 읽었을 때는 왜 더 좋은 합의 알고리즘이 이미 나와있는데 결함 상황에 자동으로 대처하기 힘든 PBFT를 많이 쓰지? 생각했는데 RBFT 의 결함을 분석해보니 그럴만하다고 생각이 들었다. public 블록체인들은 primary 를 네트워크 운영측의 관리와 네트워크 거버넌스 정책으로 악의적인 노드가 되지 못하도록 잘 관리할 것이라는 전제 아래 PBFT 를 택했을 가능성이 크다. primary 가 건전하다는 전제 아래에서는 네트워크가 3f+1 의 노드들로 운영되는 것만 잘 유지하면 되기 때문이다.
2.Hyperledger-Indy
Hyperledger-Indy 에서는 RBFT 프로토콜 기반에서 조금 수정을 가한 Plenum BFT 라는 합의를 사용한다. Indy가 private 블록체인 네트워크를 상정하고 개발되었지만, RBFT 의 위와 같은 문제를 어떻게 해결해 가고 있는 지는 관심있게 지켜볼만한 주제이다. 단순히 white-paper나 코드만 볼 것이 아니라 커뮤니티의 이슈 트래킹을 중심으로 추후에 분석해봐야 할 것 같다. (사실 Hyperledger 프로젝트들이 문서화가 잘 되어있지는 않아서, PlenumBFT 가 RBFT 의 어떤 문제를 어떻게 해결하고 있는지는 문서화 되어 있는 것이 없다.)
소프트웨어에서는 답 보다는 문제 풀이 과정에서 좋은 아이디어를 얻을 수 있다. 답만 아는 것은 오히려 사고가 확장되지 못하게 스스로 담장을 둘러치는 꼴이다.